Philosophy for Children (P4C) – trial 2
Still doesn’t work. Really doesn’t. Not even a tiny benefit.
Five years ago a rather nice randomised trial, run by the Education Endowment Foundation (EEF) (click here), tested the effect on reading and writing, of teaching philosophy to primary school children. The result was negative, but unwisely the EEF entrusted evaluation to a group of educationalists who were determined to find a positive result. By ignoring their original analysis plan, doing a data-driven analysis of change scores, and picking a favourable subgroup, children entitled to free school meals, they managed to convince themselves that teaching little children to be kind to their teddy bears helped wth reading and maths (click here for my analysis of where they went wrong). The newspapers picked up the story and headlines flew round the world (click here).
Fortunately I wasn’t the only one to smell a rat (see here and here). Professor Gorard, the lead evaluator, sent me a patronising email and blocked me on social media, but the EEF did the right thing. They realised they’d boobed, decided not to published the misleading analysis in a peer-reviewed journal [but see footnote], and did the trial again. The results are just in (website here, main report here, or for those with access problems Philosophy_for_Children_report_-_final_-_pdf).
The second trial, P4C-2, was also a cluster design but larger, 75 intervention and 123 control schools, compared with the original trial’s 26 intervention and 22 control. The protocol (click here) and analysis plan (click here) were published and adhered to. The biggest risk with cluster trials is differential recruitment or measurement of outcomes related to knowing the cluster, but this was avoided by using the 2019 Key Stage 2 (KS2) reading scale score as the primary outcome. KS2 reading and maths are measured independently on all pupils in the country, whether or not they or their schools participated. Since Gorard’s data dredging had shown the most “benefit” among children receving free school meals, the primary analysis was planned for this group. Analysis was by intention to treat.
The report is 125 pages long, and a turgid read, – education researchers love making simple things complicated – but the essence is easy to describe. There is a CONSORT flow diagram (Fig 1, p33 not shown here), few pupils were lost to follow-up (Table 12, p36 not shown here), and the randomisation achieved a balance of both schools and pupils at baseline (Table 13, p37 not shown here). The primary and main secondary outcomes are in Table 14, p38 (click on thumbnail to read).
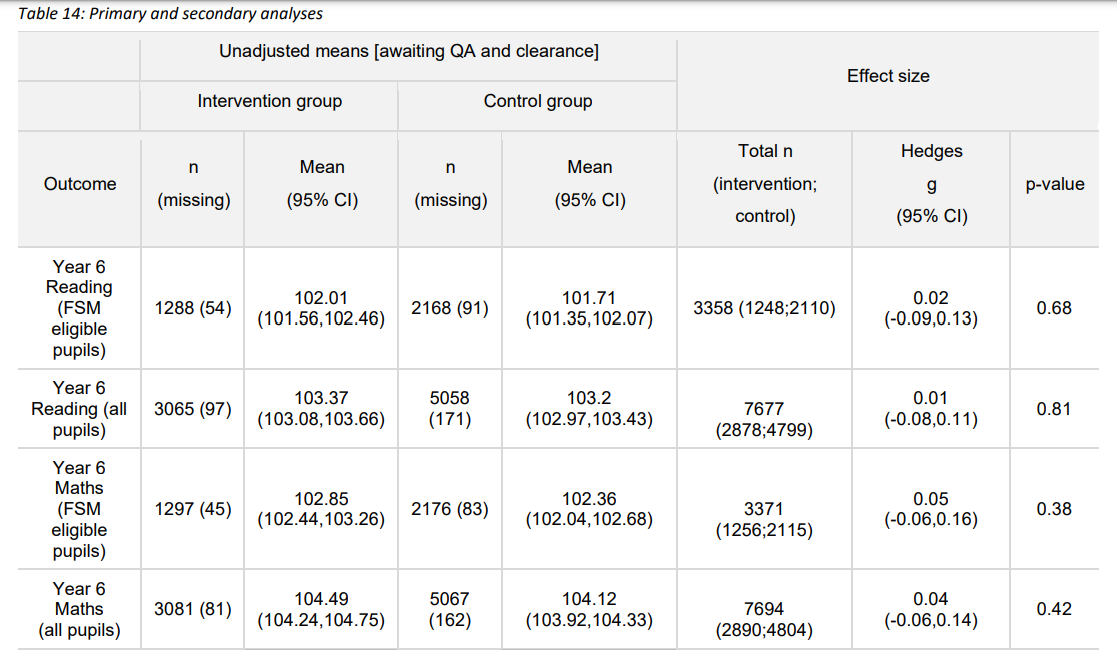
The presentation is rather strange. For each group they report the mean score and the 95% confidence interval for the mean. The actual score distributions are relegated to appendix I, p98.

Don’t be mislead by the words intervention and control into reading these as distributions by group. Perish the thought that an educationalist would ever show you anything remotely near to the raw data! These are pooled results for reading and maths, each for the whole sample and the free school meals subgroup; four distributions in total. They tell us nothing about the effect of the intervention, but they allow the reader to see that scores are roughly normally distributed with mean values between 100 and 105, a range of 80-120 and a standard deviation of roughly 12.
Turning back to table 14 above we can see that the absolute mean differences between group are tiny fractions of a single score point, i.e trivial. The Hedges g column expresses the difference as a fraction of the pooled standard deviation. Tiny by any standards. Even those educationalists who prefer the effect size to significance testing, ignore effect sizes of <0.2 and generally only consider one of >0.4 as “meaningful”. These are 0.01 to 0.05. For frequentists like me, despite the large sample size, the result is not remotely “statistically significant”.
The rest of the report discusses how well various schools implemented the intervention and searches for a signal related to how well P4C was implemented, but finds nothing.
In summary a well-designed and well-analysed negative trial. We can be confident of the result, and confident also that the trial has not missed a worthwhile small effect.
Some Twitter commenters have said, “But surely we don’t teach moral philosophy to help chidren with reading or maths. We do it to help them grow up to be better kinder people.” They make a good point. The trial says nothing about the effect of P4C on moral behaviour, and everyone supports primary school teachers continuing to teach their pupils to be kind and honest. But education planners should stop paying large sums to Sapere, the creator of P4C, and displacing lessons to teach it, in the hope of improving reading and maths.
It’s a ground-breaking trial
I wonder where it will get published. In my field a negative, large well-conducted cluster trial like this, – the AFFIRM trial of encouraging awareness of fetal movements in pregnancy for example – doesn’t languish in an obscure specialist journal but gets published as a full length paper in the most prestigious medical journal in the world, The Lancet (click here). This report will need a rewrite, but a major general science journal, Science or Nature, should publish it for its methodological importance.
The EEF has shown how to evaluate an educational intervention properly. Imagine if they used the same methods to compare phonics with whole language to teach reading, or to test whether drilling children in tables was helpful or harmful. Imagine that!
Jim Thornton
Footnote added 13 March. I’d missed it. The EEF did publish the misleading analysis in a peer reviewed journal, (click here or 1467-9752.12227), albeit with weaker conclusions. “… for […] attainment outcomes in the short term, an emphasis on developing reasoning is promising, especially for the poorest students, but perhaps not the most effective way forward.”

If you are measuring student achievement with key stage 2 tests, then anyone who suggests that one should ignore effect sizes less than 0.2 does not know what they are talking about.
Agree. Imagine a medical intervention, e.g. an iron tablet, that shifted the mean of anything meaningful, e.g. haemoglobin concentration, by 1/5th of a standard deviation. We’d say, “It works”. And we’d be right. Problem in education, it seems to me as an outsider, is not what effect size matters, but judging causation for any intervention, when researchers rarely randomise, and when they do, analyse their results as badly as they did for P4C-trial-1.
I agree that establishing causation in education is difficult, but it’s for a number of reasons, including clustering in the data (most educational interventions are heavily mediated by the teacher, so the N is really the number of teachers, or even schools, rather than the number of children), the fact that the interventions are not precisely enough defined to be researchable, and by the fact that, for example, in year 6, a 25% increase in the rate of learning would have an effect size of around 0.1 so most educational experiments are significantly underpowered. Then there is the problem caused by outcome switching, and failure to control for multiple comparisons. Randomization can be done (as in EEF’s evaluation of the “Embedding formative assessment” programme that Siobhan Leahy and I wrote) but it needs large, long studies, with precisely defined interventions.
I reviewed that trial a couple of years ago. https://ripe-tomato.org/2018/07/31/the-embedding-formative-assessment-efa-trial/ Seemed pretty good to me, given all the difficulties.
I was irritated by the analysis because the reported effect size of 0.1 included schools that had prior involvement in a similar programme. If one is trying to evaluate a new drug, and found out that some of both the control group and the treatment group had had some exposure to the drug, then I think it would be appropriate to remove these from the analysis and compare outcomes for those never having had the drug with those who were having the drug for the first time in the experiment. In the case of the EFA trial, I think the NIESR evaluators should have changed their pre-registration immediately they discovered this issue (so as to avoid being accused of hypothesizing after results were known), and the only analysis should have been comparing Attainment 8 in the 66 control group schools with no prior involvement in formative assessment with the 58 schools given access to EFA for the first time in the evaluation trial. This yields an effect size of 0.13, significant at the 0.05 level. Since one year’s learning for year 10 and year 11 students is about 0.3 standard deviations, this equates to a 20 to 25% increase in the rate of progress in the experimental group. Given that the programme took around 1% of teacher time, then this seems like a worthwhile use of teacher time.
Makes sense to this outsider. Although I guess you have skin in the game. 🙂 Is EFA or its variants universal now? Is there a NICE for education that mandates it? If not, is another trial in truly “EFA free” schools planned?
Obviously I do have skin in the game, but I think that the real problem is that, due to the work of hyper-aggregators like Robert Marzano and John Hattie, people have inflated expectations of the effect sizes that are likely to be obtained in real settings, over a period of a year, using standardized achievement measures. This means that people tend to look for “the next big thing” rather than doing the last big thing properly. A medical comparison might be with hand hygiene. Effective, but not very sexy, and hard to get people doing it consistently…
And there is nothing like NICE in education. Even if there were, I am not sure there is much of a culture of evidence in schools. Look how much difficulty we are having getting the teaching of reading right in primary schools…