Balloon disimpaction of the fetal head at Caesarean birth
Was NICE fooled?
On 16 November 2022 the National Institute for Clinical Excellence (NICE) published IPG744, Advice on Balloon disimpaction of the baby’s head at emergency caesarean during the second stage of labour. The authors concluded (click here):
New evidence seen by NICE’s interventional procedures advisory committee showed the procedure was safe and effective to be used by maternity staff trained in managing impacted babies’ heads during an emergency caesarean birth.
For the full guidance and supporting documentation (click here).
Three randomised trials were considered. One is behind a paywall, and one in a hard to access journal, but I’ve uploaded pdfs.
Seal SL, Dey A, Barman SC et al. (2016) Randomized controlled trial of elevation of the fetal head with a fetal pillow during cesarean delivery at full cervical dilatation. International Journal of Gynaecology and Obstetrics 133: 178–82 (click here, pdf here).
Sengupta M, Dutta S (2019) A comparative study of maternal and foetal outcome between reversed breech extraction technique and foetal pillow, during caesarean section in full dilatation (CSFD), in second stage of labour. Journal of Evolution of Medical and Dental Sciences 8: 1463–68 (click here, pdf here).
Lassey SC, Little SE, Saadeh M et al. (2020) Cephalic elevation device for second-stage cesarean delivery: a randomized controlled trial. Obstetrics and Gynecology 2020 135: 879–84 (click here, pdf here).
Seal et al. 2016 (click here, pdf here).
The Seal trial was the subject of an extensive critique by Andrew Grey on PubPeer in 2020 (click here). The trial was registered late and may have not had research ethics approval in one of the two recruiting centres. More importantly, an abstract reporting 202 participants was presented at the RCOG world congress in Liverpool on 24th to 26th June 2013 (click here). Although the trial recruited “between April 1, 2013, and March 31, 2014” the closing dates for abstract submission at that congress was 14 January 2013 (click here, screenshot here). i.e. 202 participants were recruited before the trial started!
The same group of authors had previously reported a series of second stage Caesarean births (click here or pdf here) (Andrew Grey paper 3), and a non-randomised study of the fetal pillow with historical controls (click here or pdf here) (Andrew Grey paper 2). Although the series in Andrew Grey paper 2 and the historical controls were the same cohorts, there were a number of differences in the results tables. Grey also identified some significant differences between the control group (no fetal pillow) in the Seal RCT and the doubly reported historical control group from the same centres. See below for the table prepared by Grey

Inconsistency between the two cohorts does not, in itself, invalidate the trial, but some differences between the trial control group and the cohorts are hard to explain. For example mean operation times were almost identical (53.9 v 52 minutes) but incision to delivery time was almost halved in the trial control group (4.95 v 8.43 minutes). Rates of total uterine wound extension were fourfold higher in the trial controls 43 (35.8%) v 10 (8.06%) and severe extensions doubled 39 (32.5%) v 19 (15.2%).
Finally the trial was reported in three separate abstracts, at the RCOG British Congress in Liverpool 2013 as a poster (abstract mentioned above), and at the RCOG World Congress, 2015, 12–15 April, Brisbane, Queensland, Australia (click here) as both a poster and oral abstract (click here). The three abstracts are reproduced below.

The recruitment periods and numbers reported in the three abstracts and the paper are summarised in the following table.
| Liverpool | Brisbane poster | Brisbane oral | Paper | |
| Recruitment period | 12 months | 14 months | 12 months | “Between April 1, 2013, and March 31, 2014” (12 months) |
| Nos. randomised | FP 100 No FBP 102 | FP 119 No FP 121 | FP 121 No FP 119 | FP 120 No FP 120 |
The shorter recruitment period and smaller numbers reported in the Liverpool abstract could be explained if recruitment was incomplete at that time, although there is no mention of an interim analysis. The differences in recruitment numbers in the two Brisbane abstracts and the paper, although small, are difficult to explain.
Andrew Grey’s Pub Peer post, which included other problematic issues, ended with: “These wide-ranging concerns raise very important doubts about the integrity of these 3 publications [the trial and two cohort studies], and the reliability of their findings. They could be addressed by independent scrutiny of the raw data, participant records, and ethics oversight documents.”
Dr Seal replied the same month, October 2020: “We have already responded to the journal editor about the queries. I will respond to your queries as soon as we receive answers from the editor. It may take some times. Thanks Dr subrata lall seal.”
As of November 2022, he has not responded further.
Immediately after Dr Seal’s response, the trial paper’s corresponding & senior author accused Grey and Pub Peer of libel in a long rant, ending with; “We are putting PubPeer on notice to withdraw their defamatory statements and publicise this to limit their libelous damages about our publications and devices.” Two further responses from that person were moderated by Pub Peer.
In summary, at best these data are unreliable and should not be used until the authors explain the inconsistencies and provide a full dataset. At worst the data are fabricated.
Sengupta & Dutta 2019 (click here, pdf here)
The Journal of Evolution of Medical and Dental Sciences is not indexed on Pubmed but the article has a doi through which it can be found on Pub Peer.
NICE treated this as a randomised trial because the section “Data Collection Technique” reads as follows:
“The two techniques were applied simultaneously in the patients. The data was collected in pre-designed and pretested schedule. Randomization was computer generated. Treatment allocation was written on index cards and concealed in identical, sealed, opaque, sequentially numbered envelopes stored in the operating room. After creation of the randomization cards, the computer-generated randomization table was deleted.”
However, the following features suggest that it was probably not a randomised trial.
- The title does not mention randomisation
- The abstract does not mention randomisation. The abstract methods describe it as “a hospital based comparative prospective study”.
- In the main text the study is also described as “Hospital based comparative prospective study”.
- In main text the Sampling Technique is as follows: “Purposive sampling technique consisting of 25 patients in each group, i.e. 25 for Foetal Pillow and 25 for Reversed Breech Extraction Technique
- There is no Consort flow diagram.
- The control group were all delivered by reverse breech extraction, an unusual method for delivering a deeply engaged head, generally used after other methods have failed. This therefore points to purposive sampling of 25 patients delivered this way.
Even if the trial was randomised, the results are problematic. The baseline table, table 1, reproduced below, does not report demographic details by group, but inappropriately adds three P values in the right hand column. It is not clear to what these refer.
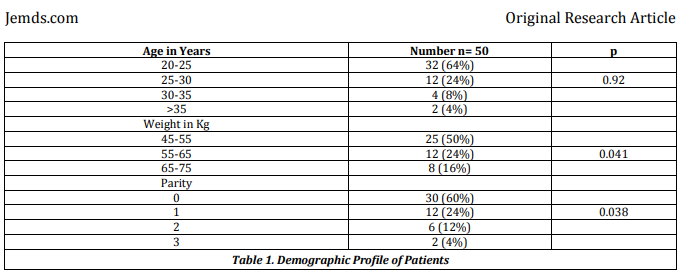
The same issue affects the obstetric variables, table 2, reproduced below.

The results table, table 3, reports outcomes by group, but contains incorrect P values, and in two cases incorrect totals for the reverse breech extraction column, shown in red below.
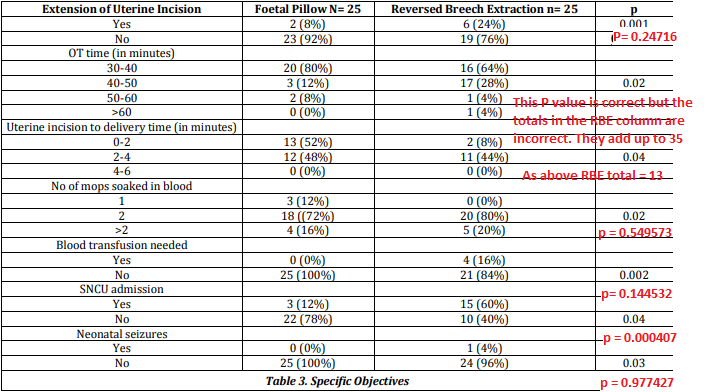
In summary this trial was probably not randomised, and even if it was, the data are not reliable. It should not be relied on, unless the authors can provide an explanation and the original dataset.
Lassey et al. 2020 (click here, pdf here)
These authors report a single centre RCT conducted from January 2018 through July 2019 at Brigham and Women’s Hospital, Boston, Massachusetts. The trial was registered here on 17 November 2017. Planned sample size 200, achieved sample size 60. It’s understandable that trials sometimes don’t reach their target – money runs out, DMECs suspend it, triallists get exhausted – but it’s disappointing that the paper is written as if 60 was the planned sample size all along.
There are other inconsistencies in eligibility, and timing of consent and randomisation. Table below.
| Registry | Paper | |
| Planned sample size | 200 | 60 |
| Eligibility | “both nulliparous and multiparous women” | “Only nulliparous women were included.” |
| Consent | First stage, 2nd stage, or after failed instrumental. “Women will be enrolled from the labor floor during their labor course when there is concern for cesarean section for failure to progress in the second stage of labor. These women may be approached if they have a prolonged labor course (before they reach full dilation), when they get to full dilation and start pushing, or following an unsuccessful operative delivery.” | First stage only “All patients who met inclusion criteria were approached on the labor floor during the first stage of labor” |
| Randomisation | As soon as consent is obtained. “Once consent is obtained, the subjects will then be randomized 1:1 into two parallel groups, the Fetal Pillow Inflated (FPI) group and the Fetal Pillow Not Inflated (FPNI) group. A random number generator will allocate the groups in blocks of ten. | Group allocation revealed to the anaesthetist after the balloon had been inserted and the patient’s legs laid flat. “If cesarean delivery was to be performed in the second stage, women were then randomly allocated to either the cephalic elevation device inflated group or the not-inflated group. An independent consultant created a computer-generated randomization scheme that used balanced treatment allocation in blocks of 10, and the resulting sequential group allocations were kept in sealed, opaque envelopes until time of randomization. At the time of cesarean delivery, the cephalic elevation device was inserted vaginally by the obstetrician after catheterization of the bladder and after vaginal preparation with betadine, per our current labor and delivery guidelines. Once the cephalic elevation device was inserted, the patient’s legs were laid flat on the operating table in accordance with the guidelines for use of this device. The delivering provider and other members of the obstetric team were blinded to whether the device was inflated or not. Group allocation was revealed to the anesthesiologist, who inflated the cephalic elevation device using 180 mL normal saline (inflated group) or did not inflate the balloon (not-inflated group).” |
These ambiguities matter because the consort flow diagram is inadequate. It simply records that 60 eligible women were randomised into two equal groups of 30. There is no mention of compliance with treatment allocation, losses to follow up or any of the myriad of other problems one would expect to arise in a trial of this complexity, conducted during an emergency second stage Caesarean section. In two cases the Caesarean followed a failed instrumental delivery, and in 14 there was also a non-reassuring fetal heart rate pattern.
To summarise, NICE has recommended that the fetal pillow is safe and effective, on the basis of one probably fabricated trial, one trial which was probably not randomised, and a third tiny trial, which failed to achieve its planned sample size and had a number of other worrying inconsistencies between registration and the final paper.
I’ve written to all three corresponding authors requesting trial source data.
Jim Thornton
Update. The Seal trial was retracted by Int J Gynecol Obstet in June 2023 (click here) and NICE reverted to its (2015) guidance the same month (click here). In brief, this describes the evidence as “inadequate in quantity and quality” and recommends use of the balloon only “with special arrangements for clinical governance and audit or research”. Good advice.
Prolific data fabricator
Mohammed Rezk from Menoufia
Dr Mohammed Rezk is Assistant Professor of Obstetrics and Gynecology at Menoufia University in Egypt. He has 71 publications on Google scholar, including 17 RCTs and 34 cohort studies. My colleagues and I first became aware of his work through two trials.
- Rezk M, Emarh M, Masood A, Dawood R, El-Shamy E, Gamal A, et al. Methyldopa versus labetalol or no medication for treatment of mild and moderate chronic hypertension during pregnancy: a randomized clinical trial. Hypertens Pregnancy. 2020;39(4):393-8.
- Salama M, Rezk M, Gaber W, Hamza H, Marawan H, Gamal A, et al. Methyldopa versus nifedipine or no medication for treatment of chronic hypertension during pregnancy: A multicenter randomized clinical trial. Pregnancy Hypertens. 2019;17:54-8.
Despite being allegedly different trials both recruited over the identical time period in the same hospital, and many result values were either identical, or within a single digit of each other – see PubPeer comment (here). No satisfactory explanation was forthcoming, and each journal eventually published an expression of concern (click here and here).
There was another unusual feature. In Rezk 2020, 69/70 categorical variables were even numbered, and in Salama 2019, all 75 were even. The probability of this happening in real data is extremely low. The same even number excess is a feature of many of his other papers (e.g. here. Tabulated here).
We were not the first to notice this. Retraction Watch recently reported that in 2017 John Carlisle, the famous fraud buster, had noticed an excess of even numbers in a trial submitted by Dr Rezk to Anesthesia (click here). He declined to publish the paper, got an evasive reply to his request for original data, and no reply at all to his request for Menoufia university to investigate. Others independently noted an excess of numbers in multiples of 5 or 10 (click here and here).
Rezk was not only undeterred – he has published 30 more papers since being called out by Carlisle – but he doesn’t seem to learn either. At least nine of these later papers contain the same highly improbable excess of even numbered categorical variables.
Last year we reviewed all 51 of Dr Rezk’s clinical papers (here or preprint). At least 35 have problems, of which to date four have been retracted, and a further eight have a published expression of concern.
If all 35 were retracted, he would be 16th equal on the Retraction Watch leader board (click here). With 51 he would make 9th place.
Jim Thornton
mPox (monkeypox) in pregnancy
Original sources
Original scientific reports of mPox in pregnancy. Summaries, links, full texts, & citations, along the lines of our Covid-19 database (click here). No opinion, reviews, or guidelines. Just primary sources. Duplicates and possible duplicates flagged. Regularly updated by Susan Bewley, Keelin O’Donoghue, Kate Walker and me. For news reports of mPox in pregnancy click here.
We’ve not listed primary sources for smallpox vaccine in pregnancy, but see reference list of study 10.
21 August 2024 – In view of the recent upsurge (click here for WHO update) we are updating this list. New studies 12-20, and 24 – 26 are all from past epidemics. Study 23 may include up to five cases from the current epidemic.
Update 29 September – MP 28 updated.
Update 30 August – MP 34 and MP 35, two authoritative reviews, added.
MP study 35 – authoritative review from NEJM
Click here or full text). Citation: Nachega JB, Mohr EL, Dashraath P, Mbala-Kingebeni P, Anderson JR, Myer L, Gandhi M, Baud D, Mofenson LM, Muyembe-Tamfum JJ; Mpox Research Consortium (MpoxReC). Mpox in Pregnancy – Risks, Vertical Transmission, Prevention, and Treatment. N Engl J Med. 2024 Aug 28. doi: 10.1056/NEJMp2410045. Epub ahead of print. PMID: 39197097.
MP study 34 – authoritative review from the Lancet
(click Paediatric, maternal, and congenital mpox: a systematic review and meta-analysis – The Lancet Global Health or full text). Citation: Sanchez Clemente N, Coles C, Paixao ES, Brickley EB, Whittaker E, Alfven T, Rulisa S, Agudelo Higuita N, Torpiano P, Agravat P, Thorley EV, Drysdale SB, Le Doare K, Muyembe Tamfum JJ. Paediatric, maternal, and congenital mpox: a systematic review and meta-analysis. Lancet Glob Health. 2024 Apr;12(4):e572-e588. doi: 10.1016/S2214-109X(23)00607-1. Epub 2024 Feb 21. PMID: 38401556.
Update 24 August – MP studies 31 to 33 added
MP study 33 – authoritative review
All cases previously reported (click here or full text). Citation: Schwartz DA, Ha S, Dashraath P, Baud D, Pittman PR, Adams Waldorf KM. Mpox Virus in Pregnancy, the Placenta, and Newborn. Arch Pathol Lab Med. 2023 Jul 1;147(7):746-757. doi: 10.5858/arpa.2022-0520-SA. PMID: 36857117.
MP study 32 – review of outcomes by viral clade
All cases previously reported (click here or full text). Citation: Schwartz DA, Pittman PR. Mpox (Monkeypox) in Pregnancy: Viral Clade Differences and Their Associations with Varying Obstetrical and Fetal Outcomes. Viruses. 2023 Jul 28;15(8):1649. doi: 10.3390/v15081649. PMID: 37631992; PMCID: PMC10458075.
MP study 31 – 27 cases from USA
Collected by CDC up to February 28, 2023. 18 pregnancies ongoing or no reported outcome. Of the other nine, three ended in pregnancy loss (<20 weeks) and six in live birth (click here or full text). Although not explicitly stated, these probably include the 23 cases reported in MP study 12. Citation: Neelam V, Olsen E, Roth N, Newton S, Galang R, Hufstetler K, Zilversmit Pao L, Peterson B, Bachmann L, Tong V, Meaney-Delman D, Ellington S. Pregnancy Characteristics and Birth Outcomes in People with Mpox Infection During Pregnancy – Surveillance for Emerging Threats to Pregnant People and Infants Network. AJOH MFM Abstract| Volume 230, ISSUE 2, SUPPLEMENT , S626, February 2024 DOI:https://doi.org/10.1016/j.ajog.2023.09.025
Update 23 August – studies 27 to 30 added. Study 27, not a primary source, included because authoritative. Study 29 included because it may have been misreported in a review. Study 30 is the previously unaccessed primary source for study 3.
MP study 30 – Primary source for Study 3
A 44-year-old woman from North Zaire contracted mPox on 11 August 1983 and recovered. On 23 September, she gave birth to a premature girl, (BW <1.5 Kg) at about the 7th month. The infant was born with generalized skin lesions characteristic for monkeypox, and the scabs had fallen off by October 7. The child died of malnutrition on November 9. (click here or full report chap 5). Citation: Jezek Z, Fenner F. Human monkeypox. New York (NY): Karger; 1988. Chapter V. Clinical Features of Human Monkeypox. p 59.
MP study 29 – a possible case from Zaire
A 2023 review (click here or full text) reported a first trimester case from Zaire, and referenced this source (click here or full report). However that paper does not report any pregnancy cases. (Note we were originally unable to access another primary source with the same first author, Jezek M. However MP study 3‘s primary source, MP study 30, has now been confirmed ). Review Citation: D’Antonio F, Pagani G, Buca D, Khalil A. Monkeypox infection in pregnancy: a systematic review and metaanalysis. Am J Obstet Gynecol MFM. 2023 Jan;5(1):100747. doi: 10.1016/j.ajogmf.2022.100747. Epub 2022 Sep 9. PMID: 36096413; PMCID: PMC9555294. And Primary source citation: Jezek Z, Szczeniowski M, Paluku KM, Mutombo M. Human monkeypox: clinical features of 282 patients. J Infect Dis. 1987 Aug;156(2):293-8. doi: 10.1093/infdis/156.2.293. PMID: 3036967.
MP study 28 – nine cases from Congo
One woman who had birthed by Caesarean two weeks earlier was admitted with mPox and peritonitis and died. Eight other pregnant women are reported, of whom one miscarried in the first trimester and three between 10 and 20 weeks. In one of the latter cases mPox skin lesions were noted on the fetus. The pregnancy outcomes of the other four are not reported (click here or full text). Citation: Leandre Murhula Masirika, David F. Nieuwenhuijse, Pacifique Ndishimye, Jean Claude Udahemuka, Bilembo Kitwanda Steeven, Nzigire Barhatwira Gisèle, Jean Pierre Musabyimana, Baganda Ntahuma Daniel, Théophile Kiluba wa Kiluba, Franklin Kumbana Mweshi, Polepole Ngabo, Theophile Tambala, Mazambi Mambo Divin, Bahati Mutalemba Chance, Léandre Mutimbwa Mambo, Leonard Schuele, Justin Bengehya Mbiribindi, Gustavo Sganzerla Martinez, David J Kelvin, Gaston Lubambo Maboko, Bas B. Oude Munnink, Trudie Lang, Frank M. Aarestrup, Christian Gortazar, Marion Koopmans, Freddy Belesi Siangoli. Mapping the distribution and describing the first cases from an ongoing outbreak of a New Strain of mpox in South Kivu, Eastern Democratic Republic of Congo between September 2023 to April 2024. medRxiv 2024.05.10.24307057; doi: https://doi.org/10.1101/2024.05.10.24307057
Update 29 Sept 2024. Study 28 has been updated, albeit still a preprint (click here or full text). The update reports 14 pregnant women, of whom 8 had a fetal loss.
MP Study 27 – a review article
Comment by David A Schwartz, a leading authority on the mPox epidemics in West Africa, on the 2023-24 epidemic pregnancy risks (click here or full text). Not a primary source. Citation: Schwartz DA. High Rates of Miscarriage and Stillbirth among Pregnant Women with Clade I Mpox (Monkeypox) Are Confirmed during 2023-2024 DR Congo Outbreak in South Kivu Province. Viruses. 2024 Jul 13;16(7):1123. doi: 10.3390/v16071123. PMID: 39066285; PMCID: PMC11281436.
MP study 26 – PAHO situation report Nov 2022
This report from the Americas refers to 31 cases in pregnant women, collected by WHO, five of whom were hospitalised (click here or full text). These probably overlap with the WHO cases in MP study 23. Citation: Situation Report on Monkeypox Multi-Country Outbreak Response – Region of the Americas. N.5 – 13 December 2022. Accessed 22 August 2024
MP study 25 – two cases from Nigeria
One pregnancy loss following ruptured membranes at 16 weeks.This case may be the same as the one reported in MP study 2. One female baby aged 28 days with bronchopneumonia and encephalitis and died after 8 days (click here or full text). Citation: Ogoina D, Iroezindu M, James HI, Oladokun R, Yinka-Ogunleye A, Wakama P, Otike-Odibi B, Usman LM, Obazee E, Aruna O, Ihekweazu C. Clinical Course and Outcome of Human Monkeypox in Nigeria. Clin Infect Dis. 2020 Nov 5;71(8):e210-e214. doi: 10.1093/cid/ciaa143. PMID: 32052029.
MP study 24 – two cases from the Share-Net collaboration
Both pregnancies ongoing. Country not reported (click here or full text). Citation: Thornhill JP, Palich R, Ghosn J, Walmsley S, Moschese D, Cortes CP, Galliez RM, Garlin AB, Nozza S, Mitja O, Radix AE, Blanco JL, Crabtree-Ramirez B, Thompson M, Wiese L, Schulbin H, Levcovich A, Falcone M, Lucchini A, Sendagorta E, Treutiger CJ, Byrne R, Coyne K, Meyerowitz EA, Grahn AM, Hansen AE, Pourcher V, DellaPiazza M, Lee R, Stoeckle M, Hazra A, Apea V, Rubenstein E, Jones J, Wilkin A, Ganesan A, Henao-Martínez AF, Chow EJ, Titanji BK, Zucker JE, Ogoina D, Orkin CM; Share-Net writing group. Human monkeypox virus infection in women and non-binary individuals during the 2022 outbreaks: a global case series. Lancet. 2022 Dec 3;400(10367):1953-1965. doi: 10.1016/S0140-6736(22)02187-0. Epub 2022 Nov 17. PMID: 36403584; PMCID: PMC9671743.
MP study 23 – 60 cases in the WHO database
The date of infection is not reported, although 55 cases had been included before March 2024, so presumably were infected in earlier epidemics. Of the total 5, 12, and 10 were in the 1st, 2nd & 3rd trimesters respectively (33 unknown trimester, none post-partum). Median age 27.5 years. 15 hospitalized. None known to be admitted to ICU and none known to have died. No baby outcomes reported (click here). Citation: 2022-24 Mpox Outbreak: Global Trends. Geneva: World Health Organization, 2024. Available online: https://worldhealthorg.shinyapps.io/mpx_global/ Accessed 22 August 2024
MP study 22 – 4 cases from Democratic Republic of Congo
Further details of the cases reported in MP study 1 (click here or full text). Citation: Pittman PR, Martin JW, Kingebeni PM, Tamfum JM, Mwema G, Wan Q, Ewala P, Alonga J, Bilulu G, Reynolds MG, Quinn X, Norris S, Townsend MB, Satheshkumar PS, Wadding J, Soltis B, Honko A, Güereña FB, Korman L, Patterson K, Schwartz DA, Huggins JW; Kole Human Mpox Infection Study Group. Clinical characterization and placental pathology of mpox infection in hospitalized patients in the Democratic Republic of the Congo. PLoS Negl Trop Dis. 2023 Apr 20;17(4):e0010384. doi: 10.1371/journal.pntd.0010384. PMID: 37079637; PMCID: PMC10153724.
MP study 21 – Case report from Congo
Further detail of one of the cases reported in MP study 1 (click here or full text). Citation: Schwartz DA, Mbala-Kingebeni P, Patterson K, Huggins JW, Pittman PR. Congenital Mpox Syndrome (Clade I) in Stillborn Fetus after Placental Infection and Intrauterine Transmission, Democratic Republic of the Congo, 2008. Emerg Infect Dis. 2023 Nov;29(11):2198-2022. doi: 10.3201/eid2911.230606. Epub 2023 Sep 13. PMID: 37705112; PMCID: PMC10617360.
MP study 20 – Case report from Spain
A 24-year-old was infected in the first trimester and delivered a healthy baby normally at term (click here or full text). Citation: García-Hernández L, Hernández-Aceituno A, Moreno Saavedra RJ, Larumbe-Zabala E. Case report: clinical presentation of Monkeypox in pregnancy. Rev Clin Esp (Barc). 2024 Apr;224(4):245-247. doi: 10.1016/j.rceng.2024.02.009. Epub 2024 Feb 23. PMID: 38401666.
MP study 19 – two case reports from USA
Both cases, identified retrospectively from stored serum samples, had normal births at term (click here or full text). Citation: Contag CA, Renfro ZT, Lu J, Shen S, Karan A, Solis D, Huang C, Sahoo MK, Yamamoto F, Jones MS, Lin J, Levy V, Pinsky BA. Prevalence of Mpox (Monkeypox) in patients undergoing STI screening in northern California, April-September 2022. J Clin Virol. 2023 Jul;164:105493. doi: 10.1016/j.jcv.2023.105493. Epub 2023 May 15. PMID: 37220710; PMCID: PMC10184869.
MP study 18 – two case reports from USA
Both cases, identified retrospectively from stored serum samples, had normal births at term (click here or full text). Same two cases as reported in study 17. Citation: Renfro ZT, Contag CA, Lu J, Solis D, Huang C, Sahoo MK, Yamamoto F, Mah J, Jones MS, Lin J, Levy V, Pinsky BA. Two cases of MPXV infection during pregnancy in heterosexual cisgender women without classic cutaneous lesions, Northern California, 2022. IDCases. 2023 Aug 21;33:e01881. doi: 10.1016/j.idcr.2023.e01881. PMID: 37680215; PMCID: PMC10480306.
MP study 17 – Case report from USA
Infected at 31 weeks and treated with tecovirimat (click here or full text). Normal birth at 39 weeks. Baby had a positive IgG test no clinical signs. Citation: Sampson MM, Magee G, Schrader EA, Dantuluri KL, Bukhari A, Passaretti C, Temming L, Leonard M, Philips JB, Weinrib D. Mpox (Monkeypox) Infection During Pregnancy. Obstet Gynecol. 2023 May 1;141(5):1007-1010. doi: 10.1097/AOG.0000000000005170. Epub 2023 Mar 15. PMID: 36928418.
MP study 16 – No pregnancies reported in the Brazil 2022 outbreak
Among 10,169 cases (648 women) no pregnancies were reported (click here or full text). Citation: Souza IN, Pascom ARP, Spinelli MF, Dias GB, Barreira D, Miranda AE. Demographic and clinical characteristics of people diagnosed with active sexually transmitted infections among monkeypox cases in Brazil: the 2022 outbreak. Rev Inst Med Trop Sao Paulo. 2024 Apr 5;66:e20. doi: 10.1590/S1678-9946202466020. PMID: 38597520; PMCID: PMC11000497.
MP study 15 – No pregnancies among 108 infected women in Sao Paolo.
From Brazil (click here or full text). No pregnancies reported among 108 infected women. Citation: Coutinho C, Secco Torres Silva M, Torres TS, Peixoto E, Avelar Magalhães M, Wagner Cardoso S, Nazário G, Mendonça M, Menezes M, Almeida PM, Dias de Brito de Carvalho PR, Bia Bedin S, Almeida AM, Carvalho S, Gonçalves Veloso V, Grinsztejn B, Velasque L; INI-Fiocruz Mpox Study Group. Characteristics of women diagnosed with mpox infection compared to men: A case series from Brazil. Travel Med Infect Dis. 2023 Nov-Dec;56:102663. doi: 10.1016/j.tmaid.2023.102663. Epub 2023 Nov 8. PMID: 37949306.
MP study 14 – Case report from UK
Mother, father and newborn baby infected (click here or full text). The baby also had adenovirus co-infection, and required neonatal intensive care and ventilation. All three recovered. Citation: Ramnarayan P, Mitting R, Whittaker E, Marcolin M, O’Regan C, Sinha R, Bennett A, Moustafa M, Tickner N, Gilchrist M, Kershaw A, Rampling T; NHS England High Consequence Infectious Diseases (Airborne) Network. Neonatal Monkeypox Virus Infection. N Engl J Med. 2022 Oct 27;387(17):1618-1620. doi: 10.1056/NEJMc2210828. Epub 2022 Oct 12. PMID: 36223535.
MP study 13 – Three cases in women from Argentina. No pregnancies
Two were in cis-women one in a trans-woman. No pregnancies. Click here or full text) Citation: Sánchez Doncell J, Lemos M, Francos J JL, González Montaner P. Viruela símica: características en población femenina, Buenos Aires, Argentina [Monkeypox: characteristics in female population, Buenos Aires, Argentina]. Medicina (B Aires). 2024;84(1):143-147. Spanish. PMID: 38271941.
MP study 12 – 23 cases during or within 3 weeks of pregnancy
From the USA. Of the 21 cases diagnosed during pregnancy, three had reported outcomes, two full-term deliveries without complications (including no transmission to the infant) and one spontaneous abortion at 11 weeks (click here or full text). The newsborns of two postnatal cases developed lesions within 1 week. Both newborns received oral tecovirimat within 48 hours and were treated for 10–14 days; one received VIGIV. Both newborns responded to treatment, appeared to be in good health, and were discharged home. Citation: Oakley, L.P.; Hufstetler, K.; O’Shea, J.; Sharpe, J.D.; McArdle, C.; Neelam, V.; Roth, N.M.; Olsen, E.O.; Wolf, M.; Pao, L.Z.; et al. Mpox Cases Among Cisgender Women and Pregnant Persons—United States, May 11–November 7, 2022. MMWR Morb. Mortal Wkly. Rep. 2023, 72, 9–14.
30 July 2022 – MP study 11 added
MP study 11 – a monkeypox & pregnancy registry
A group from Switzerland who run a registry for emergent infectious pathogens and pregnancy (click here) have expanded it to collect cases of monkeypox in pregnancy (cleck here or study). Citation: Pomar L, Favre G, Baud D. Monkeypox infection during pregnancy: European registry to quantify maternal and fetal risks. Ultrasound Obstet Gynecol. 2022 Jul 9. doi: 10.1002/uog.26031. Epub ahead of print. PMID: 35809242.
13 June 2022 – MP studies 7 to 10 added
MP study 10 – 376 women in smallpox vaccine in pregnancy registry
As of September 2006, pregnancy outcome data were available for 376 women enrolled in the Smallpox Vaccine in Pregnancy Registry (click here or study). Rates of pregnancy loss (11.9%), preterm birth (10.7%), or birth defects (2.8%), were judged comparable with those in healthy referent populations. No cases of fetal vaccinia were identified. Citation: Ryan MA, Seward JF; Smallpox Vaccine in Pregnancy Registry Team. Pregnancy, birth, and infant health outcomes from the National Smallpox Vaccine in Pregnancy Registry, 2003-2006. Clin Infect Dis. 2008 Mar 15;46 Suppl 3:S221-6. doi: 10.1086/524744. PMID: 18284362.
MP study 9 – 13 pregnancies in studies of Imvanex vaccine
Thirteen pregnancies occurred during five studies of Imvanex smallpox vaccine (Live Modified Vaccinia Virus Ankara). One was terminated with an elective abortion and one ended as spontaneous abortion. All others were followed up and all women gave birth to healthy babies (click here or study p109). These cases may overlap with those in study 7. Citation: European Medicines Agency 369203/2013 Committee for Medicinal Products for Human Use (CHMP) 30 May 2013. Accessed 13 June 2022
MP study 8 – no data on tecovirimat in pregnancy
Tecovirimat SIGA is indicated for the treatment of orthopoxvirus disease (smallpox, monkeypox,
cowpox, and vaccinia complications). There are no data on its use in pregnant women (click here or study p 30). Citation: European Medicines Agency 703119/2021. Committee for Medicinal Products for Human Use (CHMP)11 November 2021. Accessed 13 June 2022
MP study 7 – 14 pregnant women in trial of live, non-replicating smallpox and monkeypox vaccine
In this Federal Drug Administration report 24 women became pregnant during controlled trials of the Live, Non-replicating Smallpox and Monkeypox Vaccine, Modified Vaccinia Ankara BN (MVA-BN). 14 had received active vaccine or placebo. Five gave birth to healthy infants, and three had elective (non-medically indicated) abortions. In the MVA-BN group one had fetal death at ~12 weeks and one had a spontaneous abortion. In the placebo group, two had spontaneous abortions. Four women were lost to follow-up and the pregnancy outcomes are unknown (click here or study p 123). Citation: JYNNEOS, also referred to as Modified Vaccinia Virus Ankara–Bavarian Nordic (MVA-BN) FDA biologics license application. Clinical Review Memorandum 9/19/2019. Accessed 13 June 2022
11 June 2022 – MP study 5 added
MP Study 6 – five cases from the Democratic Republic of Congo
This preprint includes five pregnancy cases (click here or study), of which four had been previously described in MP study 1. No details are given of the new case except that this sentence in the abstract “fetal death occurred in 4 of 5 (80%) patients who were pregnant at admission” implies that the fetus died. Citation: Phillip R. Pittman, James W. Martin, Placide Mbala Kingebeni, Jean-Jacques Muyembe Tamfum, Qingwen Wan, Mary G. Reynolds, Xiaofei Quinn, Sarah Norris, Michael B. Townsend, Panayampalli S. Satheshkumar, Bryony Soltis, Anna Honko, Fernando B. Güereña, Lawrence Korman, John W. Huggins. Clinical characterization of human monkeypox infections in the Democratic Republic of the Congo. medRxiv 2022.05.26.22273379; doi: https://doi.org/10.1101/2022.05.26.22273379
8 June 2022 – MP studies 1-5 added
MP study 5 – No cases in pregnant women in present outbreak
As of 4 June 2022 no cases of monkeypox in pregnant women have been reported by WHO, either in endemic or non endemic areas (click here). Note the report does not explicitly state that no cases in pregnancy have ocurred. Citation: The World Health Organisation. Multi-country monkeypox outbreak: situation update. 4 June 2022. Accessed 8 June 2022
MP study 4 – no pregnant women in the 2003 USA outbreak
No infected pregnant women were reported in any of the CDC reports of the 2003 United States outbreak of monkeypox (click here for the latest update). Citation: Update: multistate outbreak of monkeypox—Illinois, Indiana, Kansas, Missouri, Ohio, and Wisconsin, 2003. MMWR Morb Mortal Wkly Rep 2003;52:589–90.
MP study 3 – secondary source for a case report from Zaire
“One case of probable congenital monkeypox in Zaire has been described. At approximately 24 weeks of
gestation, a pregnant woman developed a febrile illness with a rash; monkeypox virus was subsequently isolated from a vesicular lesion. Six weeks later she delivered a 1,500-g female infant with a generalized skin rash resembling monkeypox. The child died of malnutrition at 6 weeks of age.” The source is given as Jezek Z, Fenner F. Human monkeypox. New York (NY): Karger; 1988. [Not accessed]. Citation: Jamieson DJ, Cono J, Richards CL, Treadwell TA. The role of the obstetrician-gynecologist in emerging infectious diseases: monkeypox and pregnancy. Obstet Gynecol. 2004 Apr;103(4):754-6. doi: 10.1097/01.AOG.0000114987.76424.6d. PMID: 15051569.
Update 23 August 2024 MP study 30, the previously un-accessed source, added.
MP study 2 – one case from Nigeria in 2017-18
One woman who was pregnant during her illness had a spontaneous abortion at 26 weeks (click here or study). Citation: Yinka-Ogunleye A, Aruna O, Dalhat M, Ogoina D, McCollum A, Disu Y, Mamadu I, Akinpelu A, Ahmad A, Burga J, Ndoreraho A, Nkunzimana E, Manneh L, Mohammed A, Adeoye O, Tom-Aba D, Silenou B, Ipadeola O, Saleh M, Adeyemo A, Nwadiutor I, Aworabhi N, Uke P, John D, Wakama P, Reynolds M, Mauldin MR, Doty J, Wilkins K, Musa J, Khalakdina A, Adedeji A, Mba N, Ojo O, Krause G, Ihekweazu C; CDC Monkeypox Outbreak Team. Outbreak of human monkeypox in Nigeria in 2017-18: a clinical and epidemiological report. Lancet Infect Dis. 2019 Aug;19(8):872-879. doi: 10.1016/S1473-3099(19)30294-4. Epub 2019 Jul 5. PMID: 31285143.
MP study 1 – four cases from the Democratic Republic of Congo
Four pregnant women treated in the General Hospital of Kole, in Sankuru District, Kasai Orientale Province, from March 2007 to July 2011. One was infected at six weeks (miscarriage at 9 weeks), one at 6-7 weeks (miscarriage at 8-9 weeks), one at 14 weeks (livebirth at term), and one at 18 weeks (fetal death at 21 weeks) (click here or study). Citation: Mbala PK, Huggins JW, Riu-Rovira T, Ahuka SM, Mulembakani P, Rimoin AW, Martin JW, Muyembe JT. Maternal and Fetal Outcomes Among Pregnant Women With Human Monkeypox Infection in the Democratic Republic of Congo. J Infect Dis. 2017 Oct 17;216(7):824-828. doi: 10.1093/infdis/jix260. PMID: 29029147.
Заповіт Тараса Шевченка
The tenth translation of Testament by Taras Shevchenko
The New Yorker’s May 9th issue includes two factual reports from the town of Bucha, outside Kyiv; James Nachtwey’s photo portfolio, “A Harrowed Land” (click here), and Luke Mogelson’s “The Wound Dressers” (click here).
A shell-shocked widow retrieves a book of poetry from a box under the bed in her ruined home. Nina and Lyudmyla, sisters in their seventies, lie dead in a different house. Their shelves contain the same collection.
Mogelson writes:
Widely considered the progenitor of modern Ukrainian literature, Shevchenko had contributed as much as anyone to the development of modern Ukrainian identity, distinct from Russia’s. “My Testament”, one of the poems in the book, had become a kind of anthem for protestors during the Revolution of Dignity.”
There are at least ten English translations; eight here, a ninth here. But the latest, included in The Complete Kobzar, The Poetry of Taras Shevchenko by Peter Fedynsky (click here), is not on the internet. In contrast to the rhyming original, it’s in free verse. Fedensky claims to have followed only two rules, “strict adherence to the meaning of the original, and a constant rhythm, […] facilitated by the rich vocabulary of English.” Here it is.
Testament by Taras Shevchenko When I die, then bury me Atop a mound Amid the steppe's expanse. So I may see The great broad fields The Dnipro and the cliffs, So I may hear the river roar. When it carries hostile blood From Ukraine into the azure sea... I’ll then forsake The fields and hills - I'll leave it all Taking wing to pray To God himself... till Then, I know not God. Bury me, rise up, And break your chains Then sprinkle liberty With hostile wicked blood. And in a great new family, A family of the free, Forget not to remember me With a kind and gentle word.
Cocktails for Ukraine
And poems
Soon after the first lockfown, inspired by Stanley Tucci (click here), I started filming drinks recipes (click here) for friends who missed our usual walking and canoe trips. Sometimes I added a poem. At the end of each week we zoomed, grumbled and had a cocktail.
One (click here) managed a hundred views, mainly because The Philip Larkin Society noticed it. The first verse of Sympathy in White Major is the best poem ever written about a gin & tonic. It may be the only poem written about a gin & tonic! The rest sank without trace.
Only one, the alcohol-free Nogroni (click here), deserves to be watched again, and that because my grand-daughter stole the show.
Last week, when Ukraine was invaded, I tried my hand at a Volodymyr Zelensky (click here) in honour of their brave president. Intending to be humorous, I ended on a serious note and choked up. Too lazy for a retake, it’s already had over a thousand views. A lot for me.
Yesterday The Dirty Ukranian (click here). The 5:1 ratio reminds us of Ukraine’s numeric disadvantage, and the salty pickle how bravery, morale and leadership will more than make up for it. The crocuses & daffodils supported, Tania filmed and Susie toasted. I forgot to read Auden’s poem on the 1968 Soviet invasion of Czechoslovakia.
Za nas, za vas, i za Donbas!
August 1968
The Ogre does what ogres can,
Deeds quite impossible for Man,
But one prize is beyond his reach:
The Ogre cannot master Speech.
About a subjugated plain,
Among its desperate and slain,
The Ogre stalks with hands on hips,
While drivel gushes from his lips.
W.H.Auden
The last specialty using racist charts
Deriving normal ranges from abnormal patients
Doctors do millions of different tests on patients – bloods, imaging, exercise tolerance – and always define the range of normal values on healthy people. The normal haemoglobin concentration is based on healthy participants. Even in countries where malaria is common, and many people anaemic, the same normal ranges are used.
With two exceptions, renal function and fetal biometry. Until recently some kidney doctors used different estimated glomerular filtration rate (eGFR) ranges for people with black skins, who tend to have lower values, i.e. slightly worse renal function. And some obstetricians still use special “customised” fetal size charts, for short, underweight, or ethnic minority mothers, who tend to have smaller babies.
However the lower black eGFR values are not “normal”, they reflect more pathology, raised blood pressure etc. In 2021 NICE recognised that using different normal ranges for black people was racist. It deprived them of effective treatment, and NICE revised its guidelines to a single set of normal ranges for all adults (click here).
Most obstetricians also know that being short, under or over-weight, or having dark skin, is also associated with adverse outcomes, so using special charts for such women tends to normalise pathology. Their use is heightist, weightist and racist. The WHO, and the Intergrowth-21 group, have produced unified charts based on healthy pregnancies, which most obstetricians worldwide now use.
But the UK has been slow to adjust. About half of UK maternity units still use customised charts and the RCOG, in its Green Top guidelines, still endorses them (click here).
In the 1970s Archie Cochrane awarded obstetrics the “wooden spoon” as the last specialty to implement evidence-based medicine. We’ve done better in that department since.
But right now we are the last specialty using racist charts. Fortunately the Green Top guidelines are due for revision. It’s time to put this right.
Jim Thornton
Two maternal deaths from surgical herpes
Avoidable with blunt needles
Last year a BBC investigation suggested that two young women in Kent had died from generalised surgical herpes infection, contracted from an infected surgeon, due to a needlestick injury at Caesarean section (click here).
The evidence was compelling. Herpes contracted this way is rare, but often fatal. Neither woman had a previous history of herpes, so would likely not have had prior immunity. Both were operated on in the same trust, albeit different hospitals, by the same unnamed surgeon. Kim Sampson gave birth on 3 May 2018, and Samantha Mulcahy on June 26 the same year. Both developed overwhelming herpes infections shortly after birth and died soon after.
According to emails seen by the BBC, the partial viral genome from both infections was not only identical, but also “rare”, compared with the previous 10 years of herpes samples collected by Public Health England’s North London lab. Although the surgeon was questioned, and denied having a herpetic lesion (a whitlow) on his finger, such lesions can be small and missed.
Needlestick injuries at Caesarean are common – the BBC quotes a 50 percent glove perforation rate. It was not reported whether the surgeon used a sharp or blunt needle, but the former is likely. If so, an easy opportunity to prevent the deaths of two young women was missed.
There is overwhelming evidence that blunt needles reduce needlestick injuries. It not only accords with common sense, but there have been ten randomised trials, two involving Caesarean section, and 2,961 operations included in the latest Cochrane review in 2011 (click here).
The use of blunt needles reduced the risk of glove perforations (RR 0.46; 95% CI, 0.38 to 0.54) compared to sharp needles, and self‐reported needle stick injuries (RR of 0.31; 0.14 to 0.68). It is unlikely that future research will change this conclusion.
This was followed by a Cochrane editorial (click here) in which the review was cited as an example of one “that can and should change practice”. The authors wrote “where they can be used they should be used”. They are recommended by the US Centers for Disease Control, the US Food and Drug Administration (click here), and the National Institute for Occupational Safety and Health (click here)”.
However, for some reason, NICE (click here for the March 2021 guidance), still doesn’t recommend them, and in my experience, few UK obstetricians use them. Despite the FDA and CDC recommendations things are not much better in the US. In a recent survey only 17% of fetal medicine trainees used them, and many were not even aware such needles existed (click here).
The reason for such reluctance to implement a simple safety step is unclear. They need a little more pressure to penetrate tissue, and some surgeons argue, mistakenly, that needlestick injuries matter less when everyone is screened for Hep B, Hep C and HIV. Nothing could be further from the truth. Each of these viruses caused many surgical infections until screening caught up, and if the last two years have taught us anything, new viruses are appearing all the time!
The inquest opened this week (click here) and has been adjourned to February 21. Let’s hope the coroner, Ms Katrina Hepburn, asks if the surgeon used blunt needles, and if not, why not.
This is an avoidable harm. If NICE’s recommenation had been evidence-based, maybe two young women would be alive today.
Jim Thornton
Sharp tender shock
An Arundel Tomb
Coming across it in Chichester cathedral recently, was a shock. My friends had misled me. “It’s not here” they had said. “It’s in Arundel.”

Afterwards, walking outside, a young couple asked for a photo. I told them about the tomb and poem – they didn’t know either – so I recited the final line. They promised to check it out. I started to explain how people misread it, or maybe don’t, but got “a bit o’ grit in me eye”, so had to turn away instead.
An Arundel Tomb
Side by side, their faces blurred,
The earl and countess lie in stone,
Their proper habits vaguely shown
As jointed armour, stiffened pleat,
And that faint hint of the absurd—
The little dogs under their feet.
Such plainness of the pre-baroque
Hardly involves the eye, until
It meets his left-hand gauntlet, still
Clasped empty in the other; and
One sees, with a sharp tender shock,
His hand withdrawn, holding her hand.
They would not think to lie so long.
Such faithfulness in effigy
Was just a detail friends would see:
A sculptor’s sweet commissioned grace
Thrown off in helping to prolong
The Latin names around the base.
They would not guess how early in
Their supine stationary voyage
The air would change to soundless damage,
Turn the old tenantry away;
How soon succeeding eyes begin
To look, not read. Rigidly they
Persisted, linked, through lengths and breadths
Of time. Snow fell, undated. Light
Each summer thronged the glass. A bright
Litter of birdcalls strewed the same
Bone-riddled ground. And up the paths
The endless altered people came,
Washing at their identity.
Now, helpless in the hollow of
An unarmorial age, a trough
Of smoke in slow suspended skeins
Above their scrap of history,
Only an attitude remains:
Time has transfigured them into
Untruth. The stone fidelity
They hardly meant has come to be
Their final blazon, and to prove
Our almost-instinct almost true:
What will survive of us is love.
Philip Larkin
Evie Toombes’ Wrongful Birth
Spina bifida and folic acid
Many were startled last week to learn that Evie Toombes, who has a type of occult spinal lesion, a lipomyelomeningocele, which would not have been prevented by her mother taking folic acid, will be awarded damages against Dr Mitchell, her mother’s GP, who had failed to advise her correctly about taking folic acid. Evie is “an occasional wheelchair/Zimmer frame user”, and needs to self catheterise, but is also “a para-horse rider, a campaigner for hidden disabilities and together with her mother, the author of a book”. Click here for the news story, and here or here for the full judgment.
An earlier court had already ruled on the principle; if, with correct advice, Evie’s mother would have delayed conception, Evie would never have been born and another healthy child replaced her, Evie would be entitled to damages.
There are parallels here with abortion for fetal abnormality. In the 1970’s the Oxford philosopher, Richard Hare, argued that parents considering abortion should decide in the interests of all their potential future children. A mother carrying a fetus with spina bifida should abort in the interests of her, unconceived, but likely to be healthy, replacement child (click here). In my experience this is how many parents think, and I guess the legal arguments follow this sort of logic too. I find the earlier court’s decision rather congenial.
But the judge’s ruling that the doctor’s advice was so bad that no responsible body of GPs would have advised Evie’s mother that way, does seem harsh.
Imagine Dr Mitchell, back when the claim started, getting a lawyer’s letter presumably alleging that he’d failed to advise Evie’s mum to take folic acid. Imagine him pulling his 27 February 2001 note to read “Preconception counselling. adv. Folate if desired discussed” (judgment para 31). He must have felt out of the frame.
But here’s para 61. Both sides agree that Mrs Toombes had attended for preconception counselling at her own instigation.
“I find that Dr Mitchell’s note is completely inadequate. As I have found, Mrs Toombes’ main concern was with regard to stopping the pill and that is not referred to in the note at all. I find that Dr Mitchell’s assumption that “Folate if desired,” means that he gave his usual standard advice, but that Mrs Toombes raised an issue as to whether or not the supplement was necessary and he explored details of her diet, informed her of the risks and then left it to her to choose, is nothing but speculation after the event. The note gives the impression without more discussion that Mrs Toombes was told that she should take folic acid if she wanted to. I accept Mrs Toombes’ evidence that she came away from the consultation under the impression that if she had a healthy diet, folic acid supplements were not necessary. In the circumstances, I prefer the evidence of Mrs Toombes and find that she was not told about the recommended dose or the reason why folic acid supplementation was recommended or that it should be taken before conception and for the first 12 weeks of pregnancy.”
Nothing wrong with the judge making findings of fact. But we can now see the aspects of Dr Mitchell’s advice, that were so bad that apparently no responsible body of GPs would follow them. Here they are.
- Qualifying his advice with a comment that folic acid was not necessary if her diet was good
- Not telling her the exact dose
- Not saying that the reason was to prevent spina bifida
- Not saying that it should be given pre-conception
To a woman who was knowledgable enough to arrange preconception counselling! We used to think obstetricians had it tough.
Jim Thornton
Gynaecological effects of Covid
Scientific papers reporting short and long-term effects of Covid-19 on menstruation, menarche and menopause, fertility, genital tumours, uterovaginal prolapse, female sexual function, urinary and vulval disorders, endometriosis and other miscellaneous gynaecological problems. Primary sources only. Updated regularly. Most recent first. Curated by Jim Thornton, Keelin O’Donoghue & Kate Walker.
For Covid-19 in pregnancy (click here), indirect effects on pregnancy (click here), news reports (click here) and effects of Covid-19 vaccines (click here).
8 March – GP 25 added
Gynae paper 25 – no effect of vaccination in Israel
From the IVF units, Shamir, Sheba, and Herzliya Medical Centres, Tel Aviv (click here or paper). COVID-19 mRNA vaccine did not affect the ovarian response or pregnancy rates. Citation: Avraham S, Kedem A, Zur H, Youngster M, Yaakov O, Yerushalmi GM, Gat I, Gidoni Y, Hochberg A, Baum M, Hourvitz A, Maman E, COVID-19 Vaccination and Infertility Treatment Outcomes, Fertility and Sterility (2022), doi: https://doi.org/10.1016/j.fertnstert.2022.02.025.
20 February – GP 24 added
Gynae paper 24 – case of ovarian vein thrombosis in USA
From Reading Hospital Tower Health, Reading (click here or study). Citation: DeBoer RE, Oladunjoye OO, Herb R. Right Ovarian Vein Thrombosis in the Setting of COVID-19 Infection. Cureus. 2021 Jan 20;13(1):e12796. doi: 10.7759/cureus.12796. PMID: 33628665; PMCID: PMC7893676.
6 February – GP 23 added
Gynae paper 23 – indirect effect of the pandemic on menstruation
1159 women from Andorra, Australia, Canada, Colombia, Estonia, Germany, Israel, Latvia, Netherlands, Romania, Spain, Sweden, Switzerland, UK, and USA, using the Daysy fertility device from 1 January to 30 June, in both 2019 and 2020 (click here or paper). Citation: Haile L, van de Roemer N, Gemzell-Danielsson K, Perelló Capó J, Lete Lasa I, Vannuccini S, Koch MC, Hildebrandt T, Calaf J. The global pandemic and changes in women’s reproductive health: an observational study. Eur J Contracept Reprod Health Care. 2022 Jan 18:1-5. doi: 10.1080/13625187.2021.2024161. Epub ahead of print. PMID: 35040737.
26 January 2022 – GP 16 to 22 added. GP 13 transferred to vaccines & fertility (click here)
Gynae paper 22 – vaccine response in 36 women with ovarian cancer
Centres not reported, but approved by the research ethics committee of Alexandra Hospital, Athens, Greece (click here or paper). Citation: Liontos, M.; Terpos, E.; Markellos, C.; Zagouri, F.; Briasoulis, A.; Katsiana, I.; Skafida, E.; Fiste, O.; Kunadis, E.; Andrikopoulou, A.; Kaparelou, M.; Koutsoukos, K.; Gavriatopoulou, M.; Kastritis, E.; Trougakos, I.P.; Dimopoulos, M.-A. Immunological Response to COVID-19 Vaccination in Ovarian Cancer Patients Receiving PARP Inhibitors. Vaccines 2021, 9, 1148. https://doi.org/10.3390/vaccines9101148
Gynae paper 21 – 46 cases from Argentina
Women, aged 21–41, undergoing assisted reproductive technology procedures between November 2020 and April 2021 at the following clinics; PREGNA Medicina Reproductiva, IVI Buenos Aires, Fertilis, and InVitro, all in Buenos Aires (click here or paper). Citation: Herrero Y, Pascuali N, Velázquez C, Oubiña G, Hauk V, de Zúñiga I, Peña MG, Martínez G, Lavolpe M, Veiga F, Neuspiller F, Abramovich D, Scotti L, Parborell F. SARS-CoV-2 infection negatively affects ovarian function in ART patients. Biochim Biophys Acta Mol Basis Dis. 2022 Jan 1;1868(1):166295. doi: 10.1016/j.bbadis.2021.166295. Epub 2021 Oct 27. PMID: 34718118; PMCID: PMC8550892. – Control study
Gynae paper 20 – 9 couples from Israel
Seven with female partner covid, and two with male partner, teated at Chaim Sheba Medical Center, Ramat Gan, both before the pandemic and after infection (click here or paper). Citation: Orvieto R, Segev-Zahav A, Aizer A. Does COVID-19 infection influence patients’ performance during IVF-ET cycle?: an observational study. Gynecol Endocrinol. 2021 Oct;37(10):895-897. doi: 10.1080/09513590.2021.1918080. Epub 2021 May 11. PMID: 33974475.
Gynae paper 19 – case report from Turkey
From author affiliations the Atasehir Memorial IVF Center, Istanbul (click here or paper). Citation: Demirel C, Tulek F, Celik HG, Donmez E, Tuysuz G, Gökcan B. Failure to Detect Viral RNA in Follicular Fluid Aspirates from a SARS-CoV-2-Positive Woman. Reprod Sci. 2021 Aug;28(8):2144-2146. doi: 10.1007/s43032-021-00502-9. Epub 2021 Feb 22. PMID: 33616884; PMCID: PMC7899067.
Gynae paper 18 – 2 case reports from Spain
From author affiliations the Clinica EUGIN, Carrer de Balmes 236, Barcelona (click here or paper). Citation: Barragan M, Guillén JJ, Martin-Palomino N, Rodriguez A, Vassena R. Undetectable viral RNA in oocytes from SARS-CoV-2 positive women. Hum Reprod. 2021 Jan 25;36(2):390-394. doi: 10.1093/humrep/deaa284. PMID: 32998162; PMCID: PMC7543480.
Gynae paper 18 – 9 cases from Israel
See vaccination source 23 here.
Gynae paper 17 – 14 cases from France
From the ART unit of Tenon Hospital, Paris, between June and December 2020 (click here or paper). Citation: Kolanska K, Hours A, Jonquière L, Mathieu d’Argent E, Dabi Y, Dupont C, Touboul C, Antoine JM, Chabbert-Buffet N, Daraï E. Mild COVID-19 infection does not alter the ovarian reserve in women treated with ART. Reprod Biomed Online. 2021 Dec;43(6):1117-1121. doi: 10.1016/j.rbmo.2021.09.001. Epub 2021 Sep 10. PMID: 34711516; PMCID: PMC8432972.
Gynae paper 16 – 70 cases from China
From the Reproductive Medicine Center, Tongji Hospital, Tongji Medical College, Huazhong University of Science and Technology between May 2020 and February 2021 (click here or paper). Citation: Wang M, Yang Q, Ren X, Hu J, Li Z, Long R, Xi Q, Zhu L, Jin L. Investigating the impact of asymptomatic or mild SARS-CoV-2 infection on female fertility and in vitro fertilization outcomes: A retrospective cohort study. EClinicalMedicine. 2021 Aug;38:101013. doi: 10.1016/j.eclinm.2021.101013. Epub 2021 Jul 6. PMID: 34250457; PMCID: PMC8259363.
25 January 2022 – GP 15 added
Gynae paper 15 – 78 cases from China
Women of reproductive age with Covid between January 28 and March 8, 2020 from Tongji Hospital in Wuhan (click here or paper). Citation: Ding T, Wang T, Zhang J, Cui P, Chen Z, Zhou S, Yuan S, Ma W, Zhang M, Rong Y, Chang J, Miao X, Ma X, Wang S. Analysis of Ovarian Injury Associated With COVID-19 Disease in Reproductive-Aged Women in Wuhan, China: An Observational Study. Front Med (Lausanne). 2021 Mar 19;8:635255. doi: 10.3389/fmed.2021.635255. PMID: 33816526; PMCID: PMC8017139.
7 January 2022 – GP 14 added
Gynae paper 14 – vaccination & menstrual cycle length
US resident participants enrolled in the fertility-awareness application “Natural Cycles”, who recorded menstrual cycle data from October 2020 to September 2021, and were vaccinated between December 2020 and July 2021, and an unvaccinated control group (click here or paper). Citation: Edelman, Alison MD, MPH; Boniface, Emily R. MPH; Benhar, Eleonora PhD; Han, Leo MD, MPH; Matteson, Kristen A. MD, MPH; Favaro, Carlotta PhD; Pearson, Jack T. PhD; Darney, Blair G. PhD, MPH Association Between Menstrual Cycle Length and Coronavirus Disease 2019 (COVID-19) Vaccination, Obstetrics & Gynecology: January 5, 2022 – Volume – Issue – 10.1097/AOG.0000000000004695 doi: 10.1097/AOG.0000000000004695
23 December – GP 13 added
Gynae paper 13 – no effect of mRNA vaccine on AMH levels
129 women given two doses of the Pfizer-BioNTech vaccine (click here or paper). Citation: Mohr-Sasson A, Haas J, Abuhasira S, Sivan M, Amdurski HD, Dadon T, Blumenfeld S, Derazne E, Hemi R, Orvieto R, Afek A, Rabinovici J. The effect of Covid-19 mRNA vaccine on serum anti-Müllerian hormone levels. Hum Reprod. 2021 Dec 22:deab282. doi: 10.1093/humrep/deab282. Epub ahead of print. PMID: 34935913. 26 January update – transferred to Covid-19 vaccines, pregnancy & fertility, source 95 (click here).
13 December – GP 12 added
Gynae paper 12 – 8,538 vaccinated women
Volunteers participating in The Covid-19 Pandemic and Women’s Reproductive Health registry (click here or paper). Citation: Alexandra Alvergne, Gabriella Kountourides, Austin Argentieri, Lisa Agyen, Natalie Rogers, Dawn Knight, Gemma C Sharp, Jacqueline A Maybin , Zuzanna Olszewska. COVID-19 vaccination and menstrual cycle changes: A United Kingdom (UK) retrospective case-control study. MedRxiv posted December 6, 2021
30 November – GP 10 and 11 added
Gynae paper 11 – RCT of estadiol Rx in post menopausal women with Covid in India
Recruited at the Government Institute of Medical Sciences, Greater Noida, from September 10 to December 31, 2020 (click here or paper). Citation: Seth S, Sharma R, Mishra P, Solanki HK, Singh M, Singh M. Role of Short-Term Estradiol Supplementation in Symptomatic Postmenopausal COVID-19 Females: A Randomized Controlled Trial. J Midlife Health. 2021 Jul-Sep;12(3):211-218. doi: 10.4103/jmh.JMH_57_21. Epub 2021 Oct 16. PMID: 34759703; PMCID: PMC8569453.
Gynae paper 10 – 14 cases undergoing ART in France
From Tenon Hospital, Paris (click here or paper). Citation: Kolanska K, Hours A, Jonquière L, Mathieu d’Argent E, Dabi Y, Dupont C, Touboul C, Antoine JM, Chabbert-Buffet N, Daraï E. Mild COVID-19 infection does not alter the ovarian reserve in women treated with ART. Reprod Biomed Online. 2021 Sep 10:S1472-6483(21)00431-4. doi: 10.1016/j.rbmo.2021.09.001. Epub ahead of print. PMID: 34711516; PMCID: PMC8432972.
18 November – GP 8 and 9 added
Gynae paper 9 – case report (ectopic & Covid) from USA
From University of Miami, Health Systems, Jackson Memorial Hospital, Miami, Florida (click here or paper). Citation: Millan NM, Morano J, Florez L, Carugno J, Medina CA. Management of tubal ectopic pregnancy with methotrexate in the setting of symptomatic Coronavirus disease 2019 (COVID-19): A case report. Facts Views Vis Obgyn. 2021 Sep;13(3):277-281. doi: 10.52054/FVVO.13.3.030. PMID: 34555882.
Gynae paper 8 – Case report (ectopic & Covid) from Japan
From Gifu Prefectural Tajimi Hospital (click here or paper). Citation: Hayashi S, Takeda A. Gasless laparoendoscopic single-site surgery for management of unruptured tubal pregnancy in a woman with moderate COVID-19 pneumonia after administration of remdesivir and casirivimab-imdevimab: A case report. Case Rep Womens Health. 2022 Jan;33:e00368. doi: 10.1016/j.crwh.2021.e00368. Epub 2021 Nov 11. PMID: 34786352; PMCID: PMC8580554.
9 November – GP 7 added
Gynae paper 7 – Endometriosis survey from Italy
468 women diagnosed with endometriosis at Dipartimento di Scienze Mediche e Chirurgiche, Sant’Orsola-Malpighi Hospital, University of Bologna, and surveyed in May 2020 (click here or paper). Citation: Arena A, Orsini B, Degli Esposti E, Raimondo D, Lenzi J, Verrelli L, Iodice R, Casadio P, Seracchioli R. Effects of the SARS-CoV-2 pandemic on women affected by endometriosis: a large cross-sectional online survey. Ann Med. 2021 Dec;53(1):1924-1934. doi: 10.1080/07853890.2021.1991589. PMID: 34714186; PMCID: PMC8567944.
1 November 2021
Gynae paper 6 – 507 women with, & 520 without, endometriosis in Iran
No difference in rates or severity of Covid (click here or paper). A case–control study at Pars general hospital, Tehran, from May 21st to July 3rd, 2020. Citation: Moazzami B, Chaichian S, Samie S, Zolbin MM, Jesmi F, Akhlaghdoust M, Pishkuhi MA, Mirshafiei ZS, Khalilzadeh F, Safari D. Does endometriosis increase susceptibility to COVID-19 infections? A case-control study in women of reproductive age. BMC Womens Health. 2021 Mar 22;21(1):119. doi: 10.1186/s12905-021-01270-z. PMID: 33752656; PMCID: PMC7983080.
Gynae paper 5 – Haemothorax after IVF & Covid
From Conceber Centro de Medicina Reprodutiva, Curitiba, Paraná, Brazil (click here or paper). Citation: Rahal D, Kozlowski IF, Rosa VBD, Schuffner A. Hemothorax after oocyte retrieval in a patient with a history of COVID-19: a case report. JBRA Assist Reprod. 2021 Oct 4;25(4):647-649. doi: 10.5935/1518-0557.20210043. PMID: 34415132; PMCID: PMC8489828.
Gynae paper 4 – Covid, menopause & hormone therapy
Covid was more common among postmenopausal women and, within the latter group, more common among those taking menopausal hormone therapy (click here or paper). Women using the “Zoe” Covid Symptom Study app. Citation: Costeira R, Lee KA, Murray B, Christiansen C, Castillo-Fernandez J, Ni Lochlainn M, et al. (2021) Estrogen and COVID-19 symptoms: Associations in women from the COVID Symptom Study. PLoS ONE 16(9): e0257051. https://doi.org/10.1371/journal.pone.0257051
Gynae paper 3 – 237 women with Covid from China
Women aged 18 to 45 with confirmed COVID-19 who were hospitalized in Tongji Hospital, Wuhan, from 19 January to 1 April 2020 (click here or paper). Citation: Li K, Chen G, Hou H, Liao Q, Chen J, Bai H, Lee S, Wang C, Li H, Cheng L, Ai J. Analysis of sex hormones and menstruation in COVID-19 women of child-bearing age. Reprod Biomed Online. 2021 Jan;42(1):260-267. doi: 10.1016/j.rbmo.2020.09.020. Epub 2020 Sep 29. PMID: 33288478; PMCID: PMC7522626.
Gynae paper 2 – Mobile app ovulation & menstruation
No overall changes before and during pandemic in 214,426 cycles from 18,076 app users, primarily from Great Britain (29.3%) and the United States (22.6%) (click here or paper). Women using the “Natural Cycles” mobile app. Citation: Nguyen BT, Pang RD, Nelson AL, Pearson JT, Benhar Noccioli E, Reissner HR, Kraker von Schwarzenfeld A, Acuna J. Detecting variations in ovulation and menstruation during the COVID-19 pandemic, using real-world mobile app data. PLoS One. 2021 Oct 20;16(10):e0258314. doi: 10.1371/journal.pone.0258314. PMID: 34669726; PMCID: PMC8528316.
Gynae paper 1 – Menstrual symptoms in 127 self-selected women with Covid
From the Arizona CoVHORT study (click here or paper). Citation: Khan SM, Shilen A, Heslin KM, Ishimwe P, Allen AM, Jacobs ET, Farland LV. SARS-CoV-2 infection and subsequent changes in the menstrual cycle among participants in the Arizona CoVHORT Study. Am J Obstet Gynecol. 2021 Sep 20:S0002-9378(21)01044-9. doi: 10.1016/j.ajog.2021.09.016. Epub ahead of print. PMID: 34555320; PMCID: PMC8452349.
Jim Thornton, Keelin O’Donoghue & Kate Walker

{kind=link}